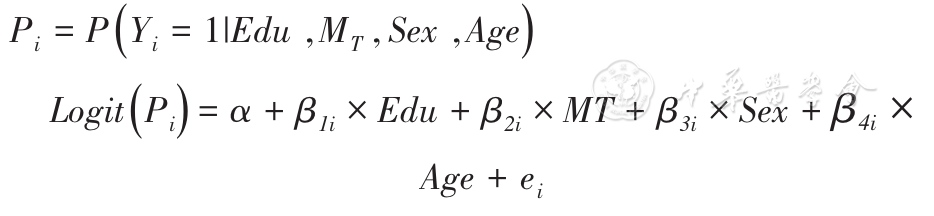文章来源: 中华精神科杂志,2019,52(3): 206-211
作者:萧潇 袁满琼 王逸凡 余博涵 韩耀风 方亚
探讨MoCA中文普通话版各条目用于厦门市老年人认知功能测评时受文化程度的影响,为MoCA的应用及条目优化提供建议。在厦门市6个区采取多阶段分层随机抽样的方法,抽取3 230名年龄≥60岁的厦门市户籍老年人,采用MoCA中文普通话版进行认知功能测评。采用单因素方差分析、Scheffe多重比较法比较不同文化程度组间MoCA得分的差异;应用SPSS 23.0软件,采用Logistic回归进行条目功能差异(differential item functioning,DIF)分析,比较MoCA原始得分与调整得分(受教育年限≤12年者,加1分)后各条目是否存在功能差异,经Bonferroni校正后P<0.000 312 5为该条目存在DIF。厦门市老年人文化程度总体较低,文盲和小学文化者分别占39.63%(1 133/2 858)和28.04%(801/2 858)。不同文化程度的老年人MoCA得分差异具有统计学意义(χ2=413.73,P<0.01),而Scheffe多重比较显示,高中文化者和本科文化者MoCA得分差异无统计学意义。不同年龄、性别老年人MoCA得分差异均有统计学意义。存在DIF的条目有:连线、复制立方体、钟表数字、钟表指针、骆驼和抽象维度的2个条目以及延迟回忆维度的4个条目等共11个条目,连线、复制立方体条目仅初中文化程度以上人群存在DIF,抽象维度的2个条目仅高中文化程度以上人群存在DIF。MoCA的多数条目适用于各个文化程度的人群进行筛查,但应用连线、复制立方体和抽象维度的2个条目时建议考虑应用人群的文化程度。
我国正步入老龄化的飞速发展阶段,老年性相关疾病日益增多,其中认知功能下降尤为突出,严重影响老年人的生活质量。适宜的认知功能测评工具在认知下降的早期识别和防控过程中至关重要。目前,认知功能测评工具众多,而MoCA因其对轻度认知功能障碍(mild cognitive impairment,MCI)和痴呆早期具有较高的灵敏度而被广泛使用[1,2]。我国于2006年开始引进MoCA,目前较常使用的有5个汉化版本:普通话版、北京版、长沙版、广州版和香港版。各个版本均依据国内外的文化差异以及地方语言特色对原版做出修订。MoCA中文普通话版敏感度为91.80%,特异度为96.10%[3],且因其具有3个平行版本,便于进行重复测量,故本次研究选用中文普通话版。国内不同版本的MoCA主要针对连线测试、延迟回忆、语言复述、抽象等条目作出修订,根据文化程度对得分的调整方式也不尽相同[4,5,6,7]。多项研究表明,MoCA得分受文化程度影响较大,容易造成测量偏倚,运用该量表测量认知功能时应考虑使用人群的文化程度[8,9]。此外,Borda等[10]因哥伦比亚人群的平均文化程度低,应用MoCA时对不同维度进行分析,得出不同维度受文化程度影响的程度不同的结论,然而该研究并未对每个条目进行分析。因此我们旨在探讨MoCA中文普通话版各条目用于厦门市老年人认知测评时受文化程度的影响,为MoCA的应用及条目优化提供建议。条目功能差异(differential item functioning,DIF)是指针对某个特定条目,对来自同一目标特质的2个平行被试组(即2组在同一目标特质的分布相同),显现出不同的统计特性[11]。
厦门市6个区(思明区、湖里区、集美区、海沧区、翔安区、同安区)年龄≥60岁的户籍老年人,且具备基本的日常生活能力者。排除有明显视听障碍、无法沟通交流、患有严重影响脑功能的各类疾病、有精神病史、不愿意参加调查的老年人。本研究经厦门大学公共卫生学院伦理委员会批准(SPH-XMU2015006),所有被调查者均对本研究知情同意,并签署知情同意书。
由于鲜有研究探讨了量表研制或改良的样本量要求,本研究参考Lam[12]使用的量表质量评估方法,采纳样本数量应不少于量表条目数的10倍。由于MoCA共有32个条目得分点,因此认为样本数量达320即符合研究要求。
于2016年7—10月,采用多阶段分层随机抽样的方法,对厦门市6个区,44个社区,年龄≥60岁的3 230名户籍老年人开展面对面的入户调查,抽样过程详见前期研究[13]。
一般人口学信息(姓名、性别、文化程度、职业、经济状况等)、日常生活能力(工具性日常生活活动能力量表)、精神状况(简版老年抑郁量表)、认知功能情况(MoCA中文普通话7.1版)等。其中,文化程度分为不识字/识字很少、小学、初中、高中/中专/技校、专科/本科及以上5个组别。MoCA的标准得分界值为:15分以下为痴呆,15~25分为MCI,26分及以上为正常;受教育年限≤12年者需加1分。
采用SPSS 23.0分析软件。一般资料的计量资料釆用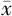 ±s进行描述;采用单因素方差分析、Scheffe多重比较法分析不同文化程度组间MoCA得分的差异;采用单因素方差分析比较不同年龄和性别老年人MoCA得分的差异;采用二元Logistic回归进行DIF分析,公式如下:
±s进行描述;采用单因素方差分析、Scheffe多重比较法分析不同文化程度组间MoCA得分的差异;采用单因素方差分析比较不同年龄和性别老年人MoCA得分的差异;采用二元Logistic回归进行DIF分析,公式如下:
其中,Edu为教育水平,MT是匹配变量MoCA总分,协变量为Sex(性别)和Age(年龄),ei为随机误差项。由于MoCA共有32个得分点,为了控制出现Ⅰ类错误的概率,采用Bonferroni校正,P<0.01/32即0.000 312 5为具有统计学意义,即认为该条目存在DIF。
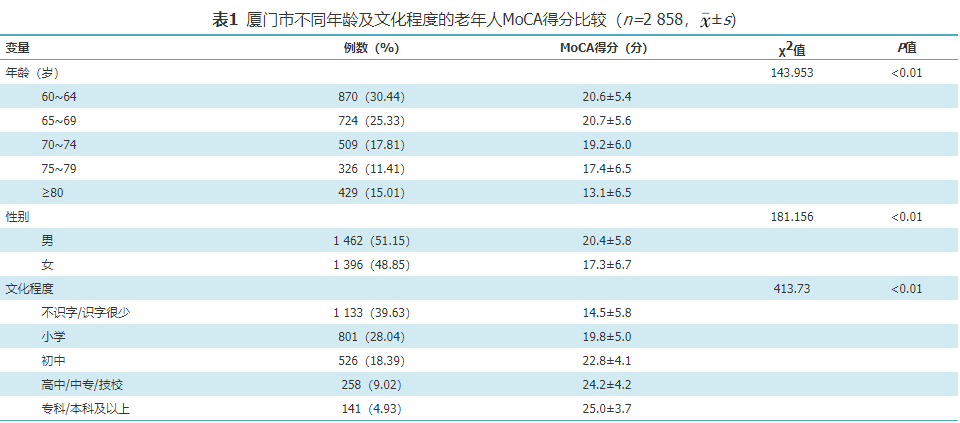
在参与研究的3 230人中,经资料审核及完整性检查,排除MoCA得分缺失者、患有头部外伤、帕金森病、卒中者、3个月内服用抗胆碱能类药物和苯二氮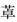 类等神经阻断类药物者,剩余2 858名被调查者数据纳入分析。其中,年龄60~64岁者占30.44%,65~69岁者占25.33%,70~74岁占17.81%,75~79岁者占11.41%,≥80岁者占15.01%;男1 462名,女1 396名;文化程度:不识字/识字很少占39.63%,小学占28.04%,初中占18.39%,高中/中专/技校占9.02%,专科/本科及以上占4.93%。不同文化程度组的MoCA得分比较见表1。单因素方差分析显示不同文化程度老年人MoCA得分差异有统计学意义(P<0.01),文化程度越高,MoCA得分则越高。Scheffe多重比较结果显示高中/中专/技校与专科/本科及以上2组MoCA得分差异无统计学意义。不同年龄老年人MoCA得分差异有统计学意义(P<0.01),年龄越高,MoCA得分越低。不同性别老年人MoCA得分差异有统计学意义(P<0.01),男性得分高于女性。
类等神经阻断类药物者,剩余2 858名被调查者数据纳入分析。其中,年龄60~64岁者占30.44%,65~69岁者占25.33%,70~74岁占17.81%,75~79岁者占11.41%,≥80岁者占15.01%;男1 462名,女1 396名;文化程度:不识字/识字很少占39.63%,小学占28.04%,初中占18.39%,高中/中专/技校占9.02%,专科/本科及以上占4.93%。不同文化程度组的MoCA得分比较见表1。单因素方差分析显示不同文化程度老年人MoCA得分差异有统计学意义(P<0.01),文化程度越高,MoCA得分则越高。Scheffe多重比较结果显示高中/中专/技校与专科/本科及以上2组MoCA得分差异无统计学意义。不同年龄老年人MoCA得分差异有统计学意义(P<0.01),年龄越高,MoCA得分越低。不同性别老年人MoCA得分差异有统计学意义(P<0.01),男性得分高于女性。
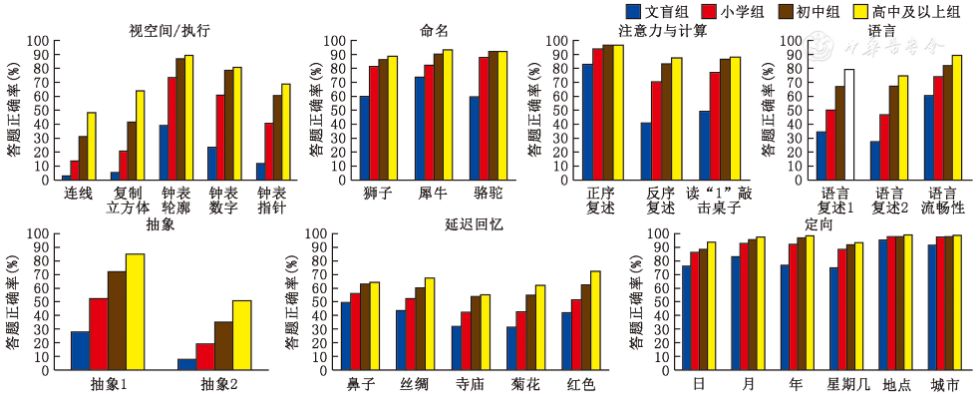
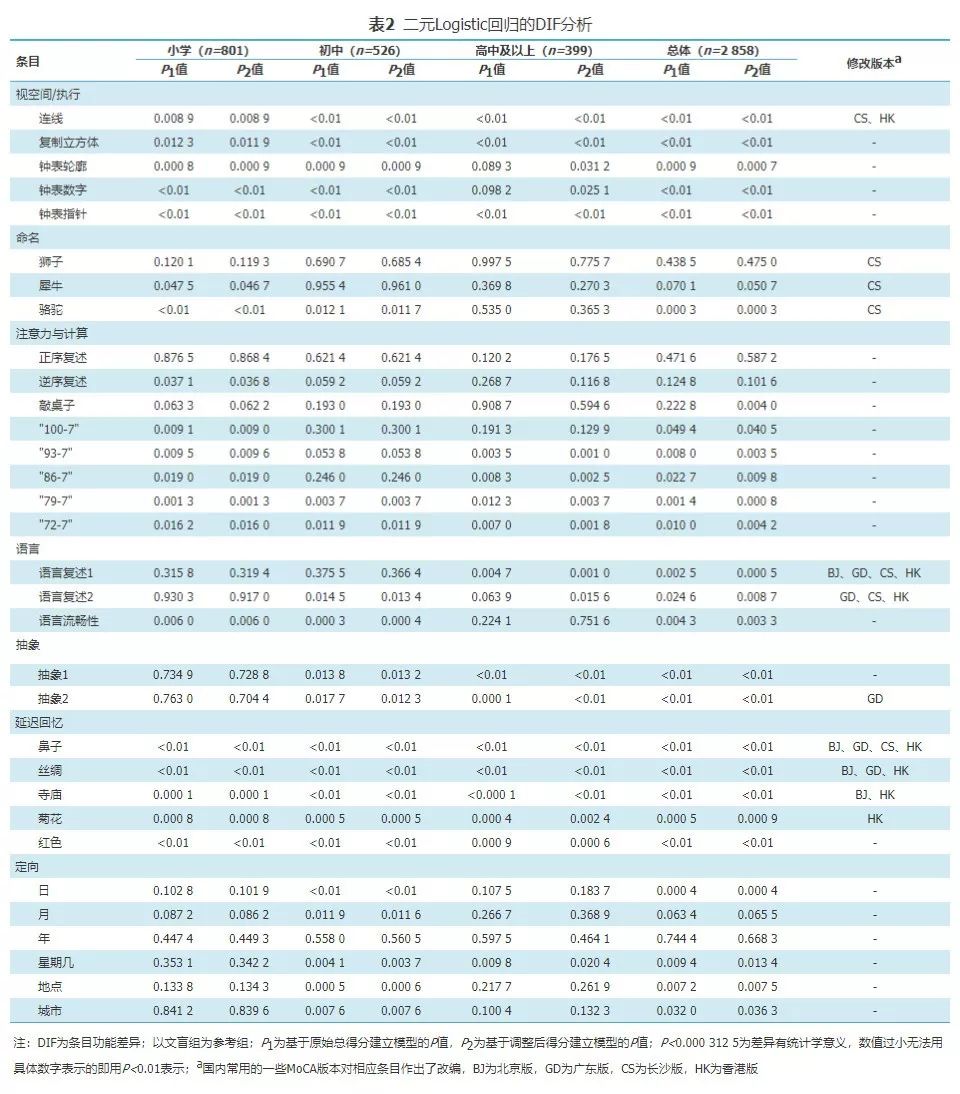
将MoCA得分差异无统计学意义的高中/中专/技校和专科/本科及以上2组合并,形成四分类文化程度,分为4组即文盲组(不识字/识字很少)、小学组、初中组、高中及以上组。各条目的答题情况见图1:视空间/执行、语言、抽象、延迟回忆4个维度的条目在不同文化程度组的人群答题正确率差异有统计学意义(P<0.01),且连线、复制立方体、抽象2等条目的总体答题正确率过低(17.6%、24.7%、22.1%)。而命名、注意力与计算、定向3个维度的条目得分受文化程度影响较小,仅文盲组的部分条目答题正确率偏低。图1 厦门市不同文化程度老年人(n=2 858)MoCA 7个维度各条目答题正确率以各条目答题正确与否作为因变量,文化程度文盲组为参考组,以MoCA总分为匹配变量,性别、年龄为协变量建立二元Logistic回归模型。由于MoCA中文普通话7.1版的标准操作流程中要求按文化程度调整总分(受教育年数≤12年者,总分加1分),为比较加分前后的条目是否依旧存在DIF,以MoCA原始总得分和调整后的总分与四分类文化程度分别建立关于各个条目的二元Logistic回归模型。采用该模型诊断出存在DIF的条目见表2。从文化程度的总体系数来看,依据原始总得分建立的模型,存在DIF的条目为:视空间/执行维度的连线、复制立方体、钟表数字、钟表指针,命名维度的骆驼,抽象维度2个条目,延迟回忆维度的鼻子、丝绸、寺庙、红色,共11个。此外,连线、复制立方体条目中,小学组与文盲组不存在DIF;钟表数字条目中,仅高中组与文盲组不存在DIF;抽象1条目中,小学组、初中组与文盲组不存在DIF;抽象2条目中,小学组、初中组与文盲组同样不存在DIF。依据调整后总得分建立的模型,存在DIF的条目与以原始得分建立模型获得的基本一致,但减少了命名维度中的骆驼条目,依然有10个条目存在DIF。
MoCA主要用于筛查MCI,但筛查的界值尚未达成共识,不同地区推荐界值不一,为17~26分不等[2,4,14]。多数研究以Petersen金标准[15]作为MCI确诊手段,采取病例对照研究的方式,通过绘制ROC曲线来确定最佳界值[5,7]。MoCA现有的加分方式仅改善了其中一个条目(骆驼)的DIF,尚有10个条目因文化程度而存在DIF。连线、复制立方体和抽象维度的2个条目情况特殊,不同文化程度间产生分界,可为加分方式提供新的思路。由于MoCA是用于筛查出现认知功能减退的人群,认知功能正常的人应该有较高的条目答题正确率,而本研究显示部分条目的整体答题正确率极低,这些条目在其他同类研究中也具有较低的答题正确率[3,9]。不同文化程度人群的MoCA得分不同可能源于部分条目的测验过分依赖于文化程度[11]。本研究进行MoCA的DIF分析,从各个条目的角度来探索MoCA与文化程度的关系。根据DIF分析结果,连线、复制立方体、钟表数字、钟表指针和抽象维度的2个条目以及延迟回忆维度的4个条目被筛选出来。孙洪吉等[16]对北京版MoCA进行条目分析,其样本为1 350名体检人群,文化程度分布为中学到研究生,以"≤1/2项目分"和"≤项目平均分"为筛选条件,认为连线、画钟测试、复制立方体、复述1、语言流畅性、抽象2、延迟回忆等条目需要进一步修改,与本研究中筛选出的存在DIF条目较为一致。国内各版本MoCA均未对注意力与计算(8个条目)、定向(6个条目)进行修订[4,5,6,7],而仅有长沙版MoCA中修订了命名(3个条目),提示这些条目的应用情况较好。而语言复述的2个条目被多个版本修改,在本研究中却未显示出DIF,可能是受到闽南语文化的影响,原因有待进一步研究。MoCA作为筛查MCI的工具,其得分不应过多地受文化程度的影响[8],而调研过程中发现,多数低文化程度老人对连线、画钟测试、抽象等条目的理解性极差,经统计分析后发现这些条目确实存在DIF。我们的研究建议对存在DIF的条目进行修订,或为不同文化程度的人群校正这些条目的分值,校正方式不局限于"受教育年数≤X年加Y分",可结合神经内科医师诊断,或影像学资料等临床指标作为MCI金标准,建立DIF校正模型。
本研究中分析了MoCA在闽南地区老年人群中的适用性,并应用DIF方法研究MoCA各个子条目与文化程度的关系,研究存在一定的局限性:(1)使用MoCA时未联用其他认知功能测评量表,无法按照Petersen金标准划定最佳界值,未来的研究可联用MMSE进行认知功能筛查;(2)未对常用语种进行变量控制,由于闽南地区的老年人惯用闽南语,可能造成语言复述等条目的DIF分析误差。
本研究中采用DIF分析法对MoCA中的条目进行分析,对比了MoCA中文普通话7.1版原始得分和调整后得分的模型,认为"受教育年数≤12年者,总分加1分"的调整方式无法完全弥补文化程度对MoCA的测量偏倚,建议结合MCI诊断金标准建立DIF校正模型,以获得较为准确的认知测量得分。MoCA量表的命名、注意力与计算、定向3个维度以及钟表轮廓、延迟回忆4(菊花)的19个条目适用于各个文化程度的人群筛查。应用连线、复制立方体条目时可考虑为初中以下文化程度人群加分,应用抽象维度的2个条目时,可考虑为高中以下文化程度人群加分。为进一步获得筛查闽南地区老年人MCI的工具,建议修订MoCA中文普通话7.1版量表中的这些条目的内容和问法:连线、复制立方体、钟表数字、钟表指针、抽象维度的2个条目以及延迟回忆维度的条目。最后,MoCA是目前用于初步筛查MCI的一个经济可行的手段,使MoCA适用于不同文化程度的人群具有重要的现实及社会意义,建议未来研究者使用MoCA时注意人群的文化程度分布。
参考文献(略)


小提示:87%用户已下载掌上医讯App,更方便阅读和交流,请扫描二维码直接下载App

(本网站所有内容,凡注明来源为“掌上医讯”,版权均归掌上医讯所有,欢迎转载,转载请注明出处,否则将追究法律责任。凡是本网站注明来源为其他媒体的内容为转载,版权归原作者所有,转载仅作分享,文章观点不作为掌上医讯观点,如有侵权,请及时联系我们,联系电话:0532-67773733)